from data chaos to decision-ready intelligence
A full-stack AWS and Databricks Lakehouse that uses RAG to turn fragmented legacy data into a high-performance knowledge engine.
#AWSBedrock #Databricks #UnityCatalog #DeltaLiveTables #Python #GitLab #CI/CD #Streamlit
Modernizing Intelligence Discovery
I’ve spent 20 years pulling systems apart to understand how they tick. Today, I apply that same forensic curiosity to the Intelligence Community’s biggest challenge: Data Saturation.
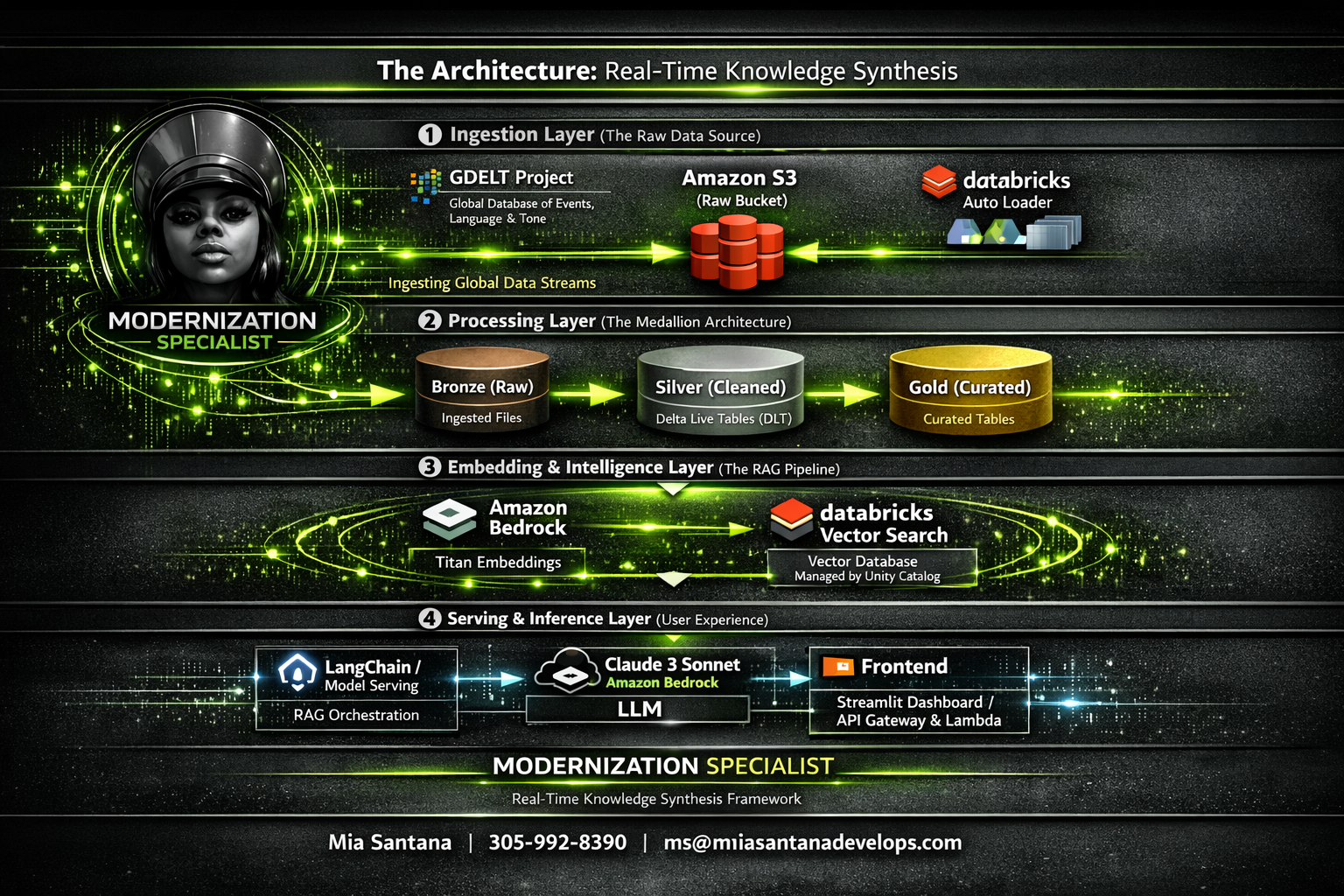
When legacy siloes create 48-hour intelligence latencies, I build the solution. I engineered a Full-Stack Knowledge Synthesis Engine that leverages AWS and Databricks to automate the path from raw field reports to verified insights. Using Medallion Architecture and RAG, I created a system where analysts don’t have to hunt for data, they simply ask for it. This IL5-ready architecture replaces manual extraction with automated semantic discovery, ensuring that in a world of endless data, the most critical insights are always the first to be found.
The modernization blueprint: data at the speed of decision
Legacy Challenge: The Intelligence Gap
Thousands of siloed, unstructured reports required manual analysis, creating a 48-hour lag between data ingestion and actionable intelligence.
Modern Solution: The Knowledge Engine
A serverless, automated pipeline that ingests and indexes data in real-time, reducing the path from raw data to natural language query to under 5 minutes.
-
Databricks Auto Loader
Auto Loader is the ingestion engine that continuously processes new GDELT files as they land in the S3 bucket. It eliminates directory rescans, handles schema drift, and scales to billions of files. For real-time pipelines it provides:
Incremental discovery of new objects
Automatic schema inference and evolution
Checkpointing for exactly-once processing
Streaming Ingestion Example:
df = (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("cloudFiles.schemaLocation", "/mnt/schemas/gdelt")
.load("/mnt/raw/gdelt/")
)
(df.writeStream
.format("delta")
.option("checkpointLocation", "/mnt/checkpoints/gdelt_bronze")
.outputMode("append")
.start("/mnt/bronze/gdelt"))
Delta Live Tables (DLT)
DLT manages the transformation pipeline from Bronze > Silver > Gold using declarative logic. It ensures reliability through automatic lineage, monitoring, and data quality enforcement.
Bronze: Raw ingested GDELT records
Silver: Cleaned, deduplicated, PII-masked, language-normalized
Gold: Curated, analytics-ready tables for embedding and RAG
Data Quality with dlt.expect
DLT expectations enforce constraints and optionally drop or fail invalid records.
import dlt
@dlt.table
@dlt.expect("valid_event_date", "event_date IS NOT NULL")
@dlt.expect_or_drop("valid_tone", "tone BETWEEN -100 AND 100")
def gdelt_silver():
df = spark.readStream.table("bronze_gdelt")
return df.dropDuplicates(["global_event_id"])
This ensures only valid, high-quality events progress to the Silver layer.
-
Why Claude 3 Sonnet via Amazon Bedrock?
Claude 3 Sonnet provides:
Large context window (200K-1M tokens) for multi-document synthesis
High factual accuracy and low hallucination rates
Fast inference suitable for real-time mission workflows
Native AWS integration, simplifying security and deployment
This makes it ideal for synthesizing GDELT-derived intelligence.
Vector Search with Databricks + Unity Catalog
Embeddings are stored in Databricks Vector Search, which is fully governed by Unity Catalog:
Centralized permissions for tables, models, and vector indexes
Row-level and column-level security
Full lineage tracking and auditability
Secure isolation across workspaces
This ensures embeddings remain protected while still enabling high-performance semantic retrieval.
LangChain Retrieval Logic
LangChain orchestrates the RAG loop by retrieving relevant vectors and passing them to Claude 3.
from langchain.vectorstores import DatabricksVectorSearch
from langchain.chains import RetrievalQA
vector_store = DatabricksVectorSearch(
index_name="gdelt_events_index"
).as_retriever(search_kwargs={"k": 5})
qa = RetrievalQA.from_chain_type(
llm=claude_llm,
retriever=vector_store
)
response = qa.run("Summarize political unrest events in South America.")
This creates a clean, modular retrieval pipeline.
-
AWS Lambda API Layer
Lambda provides a lightweight, serverless inference endpoint for your mission portal or external systems.
Bedrock Call Using Boto3
import boto3
import json
client = boto3.client("bedrock-runtime")
payload = {
"prompt": "Summarize the latest GDELT events.",
"max_tokens": 300
}
response = client.invoke_model(
modelId="anthropic.claude-3-sonnet",
body=json.dumps(payload)
)
result = json.loads(response["body"].read())
print(result["completion"])
This enables low-latency, scalable inference.
Streamlit UI
Streamlit provides a fast, interactive interface for analysts:
Real-time querying
Visualization of retrieved context
Secure integration with Lambda or Databricks endpoints
Style choice
GitLab CI/CD Snippet
A minimal pipeline step for deploying or testing Bedrock inference (yaml):
bedrock_inference_test:
image: python:3.10
script:
- pip install boto3
- python scripts/test_bedrock_inference.py
only:
- main
This ensures the RAG pipeline is validated on every merge.